Kafka 核心设计
架构设计
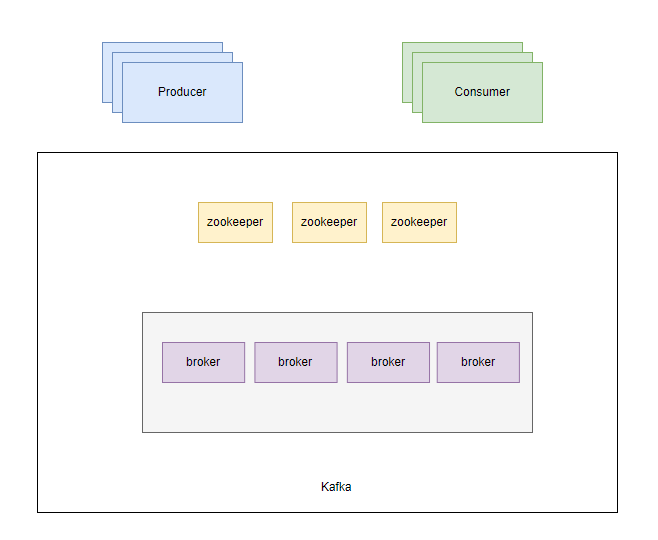
kafka 为分布式消息系统,由多个 broker 组成。消息是通过 topic 来分类的,一个 topic 下存在多个 partition,每个 partition 又由多个 segment 构成。
架构图
在 2.8 版本之前,元数据都是存储在 zookeeper,暂且使用老的架构描述。
Topic 逻辑结构
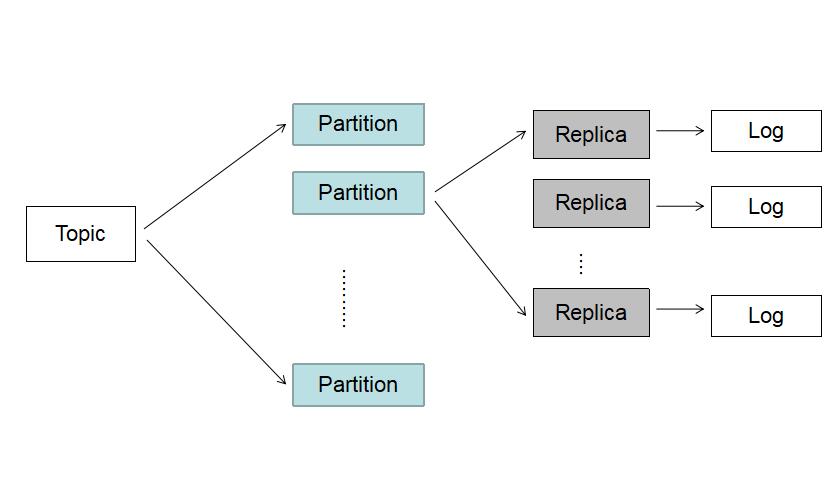
日志目录结构

数据可靠性设计
当 Producer 向 Leader 发送数据时,可以通过request.required.acks参数设置数据可靠性的级别
0: 不论写入是否成功,server 不需要给 Producer 发送 Response,如果发生异常,server 会终止连接,触发 Producer 更新 meta 数据;
1: Leader 写入成功后即发送 Response,此种情况如果 Leader fail,会丢失数据
-1: 等待所有 ISR 接收到消息后再给 Producer 发送 Response,这是最强保证
仅设置 acks=-1 也不能保证数据不丢失,当 Isr 列表中只有 Leader 时,同样有可能造成数据丢失。要保证数据不丢除了设置 acks=-1, 还要保 证 ISR 的大小大于等于 2,具体参数设置:
(1).request.required.acks:设置为-1 等待所有 ISR 列表中的 Replica 接收到消息后采算写成功; (2).min.insync.replicas: 设置为大于等于 2,保证 ISR 中至少有两个 Replica
Producer 要在吞吐率和数据可靠性之间做一个权衡
数据一致性设计
一致性定义:若某条消息对 Consumer 可见,那么即使 Leader 宕机了,在新 Leader 上数据依然可以被读到
- HighWaterMark
简称 HW: Partition 的高水位,取一个 partition 对应的 ISR 中最小的 LEO(LogEndOffset)作为 HW,消费者最多只能消费到 HW 所在的位置,另外每个 replica 都有 HW,leader 和 follower 各自负责更新自己的 HW 状态,HW<= leader. LEO
- 对于 Leader 新写入的 msg
Consumer 不能立刻消费,Leader 会等待该消息被所有 ISR 中的 replica 同步后,更新 HW,此时该消息才能被 Consumer 消费,即 Consumer 最多只能消费到 HW 位置
这样就保证了如果 Leader Broker 失效,该消息仍然可以从新选举的 Leader 中获取。对于来自内部 Broker 的读取请求,没有 HW 的限制。同时,Follower 也会维护一份自己的 HW,Folloer.HW = min(Leader.HW, Follower.offset)
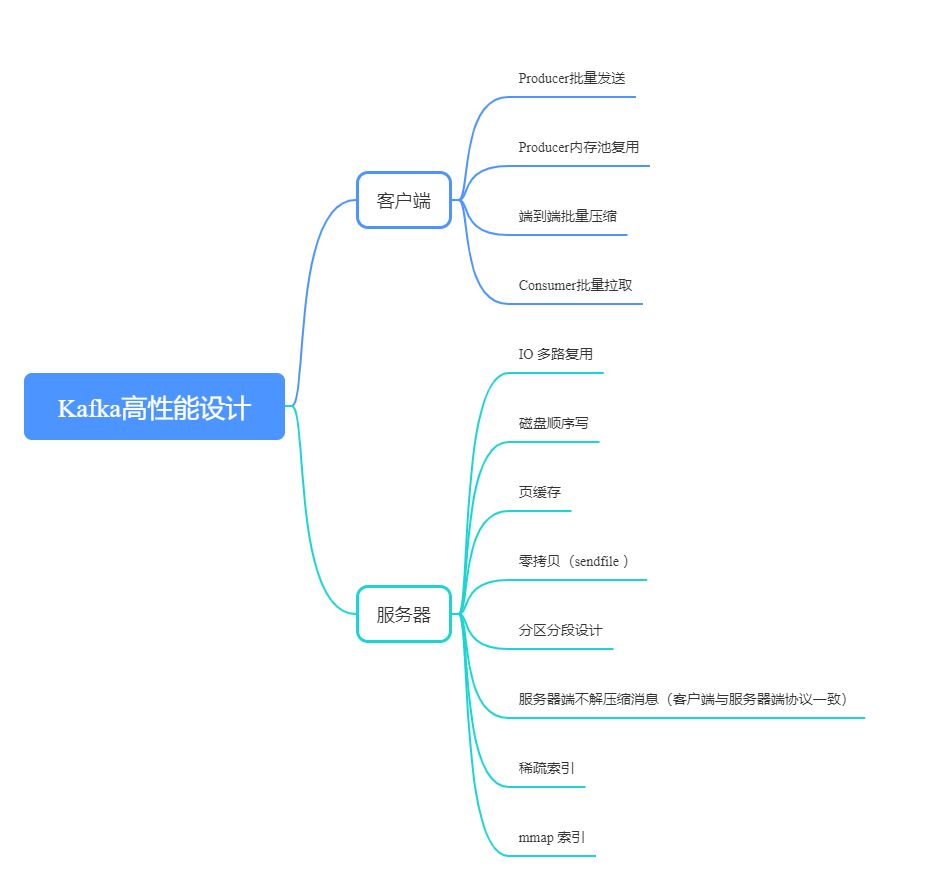
高性能设计
可以从两个方面来分析:客户端和服务器端。除了 Kafka 服务器端优秀设计之外,端到端批量压缩绝对算的上 Kafka 高性能设计的秘密武器。